
The main goal of Nextflow is to make workflows portable across different computing platforms taking advantage of the parallelisation features provided by the underlying system without having to reimplement your application code.
From the beginning Nextflow has included executors designed to target the most popular resource managers and batch schedulers commonly used in HPC data centers, such as Univa Grid Engine, Platform LSF, SLURM, PBS and Torque.
When using one of these executors Nextflow submits the computational workflow tasks as independent job requests to the underlying platform scheduler, specifying for each of them the computing resources needed to carry out its job.
This approach works well for workflows that are composed of long running tasks, which is the case of most common genomic pipelines.
However this approach does not scale well for workloads made up of a large number of short-lived tasks (e.g. a few seconds or sub-seconds). In this scenario the resource manager scheduling time is much longer than the actual task execution time, thus resulting in an overall execution time that is much longer than the real execution time. In some cases this represents an unacceptable waste of computing resources.
Moreover supercomputers, such as MareNostrum in the Barcelona Supercomputer Center (BSC), are optimized for memory distributed applications. In this context it is needed to allocate a certain amount of computing resources in advance to run the application in a distributed manner, commonly using the MPI standard.
In this scenario, the Nextflow execution model was far from optimal, if not unfeasible.
For this reason, since the release 0.16.0, Nextflow has implemented a new distributed execution model that greatly improves the computation capability of the framework. It uses Apache Ignite, a lightweight clustering engine and in-memory data grid, which has been recently open sourced under the Apache software foundation umbrella.
When using this feature a Nextflow application is launched as if it were an MPI application.
It uses a job wrapper that submits a single request specifying all the needed computing
resources. The Nextflow command line is executed by using the mpirun utility, as shown in the
example below:
#!/bin/bash
#$ -l virtual_free=120G
#$ -q <queue name>
#$ -N <job name>
#$ -pe ompi <nodes>
mpirun --pernode nextflow run <your-project-name> -with-mpi [pipeline parameters]
This tool spawns a Nextflow instance in each of the computing nodes allocated by the cluster manager.
Each Nextflow instance automatically connects with the other peers creating an private internal cluster, thanks to the Apache Ignite clustering feature that is embedded within Nextflow itself.
The first node becomes the application driver that manages the execution of the workflow application, submitting the tasks to the remaining nodes that act as workers.
When the application is complete, the Nextflow driver automatically shuts down the Nextflow/Ignite cluster and terminates the job execution.
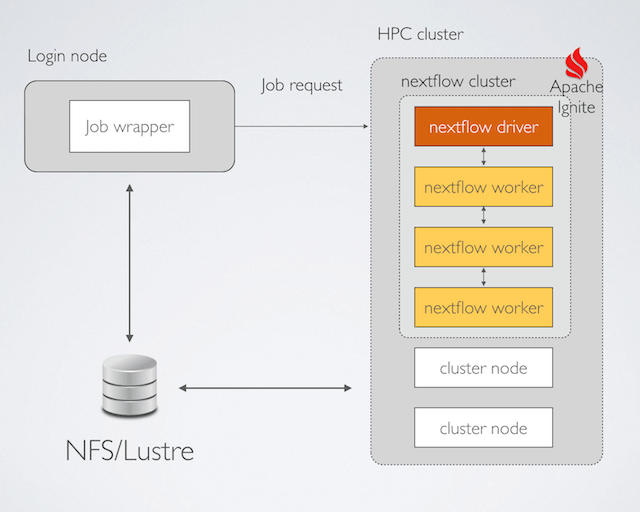
In this way it is possible to deploy a Nextflow workload in a supercomputer using an execution strategy that resembles the MPI distributed execution model. This doesn’t require to implement your application using the MPI api/library and it allows you to maintain your code portable across different execution platforms.
Although we do not currently have a performance comparison between a Nextflow distributed execution and an equivalent MPI application, we assume that the latter provides better performance due to its low-level optimisation.
Nextflow, however, focuses on the fast prototyping of scientific applications in a portable manner while maintaining the ability to scale and distribute the application workload in an efficient manner in an HPC cluster.
This allows researchers to validate an experiment, quickly, reusing existing tools and software components. This eventually makes it possible to implement an optimised version using a low-level programming language in the second stage of a project.
Read the documentation to learn more about the Nextflow distributed execution model.